
Every so often I see people asking in the newsgroups how to solve certain challenges they encounter while working on their BizTalk applications. One common question revolves around being able to go "back to the past" when an error happens during processing of a message.
This isn't a bad question at all, and usually revolves around how to simulate the behavior of atomic transactions in an environment where transactions can be a lot more complex and not always as natural.
The question usually goes like this: "I'm receiving a message in BizTalk, which is triggering an orchestration instance. The orchestration does this and that, and if it any of those things fail, I want to put the message back where I got it from".
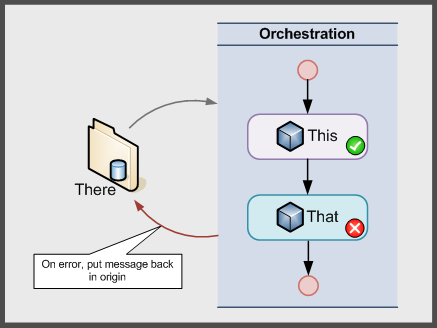
The question might seem simple, but it's not always necessarily so. In fact, sometimes you have to stop a moment and ask yourself whether this really makes sense. There are several aspects you need to consider:
- Handling the case where "this" causes an error is probably not a big deal. Handling the case where "this" succeeded but "that" failed, however, might not be that simple. Not all actions your orchestration might do can be undone.
- Most of the time you'll find that both actions can't be done as a single unit in a single atomic transaction. Fortunately, BizTalk provides very good support for long-running transactions and compensation which can help quite a bit.
Unfortunately, long-running transactions and compensation models are often misunderstood (cue in the inevitable "How long does a transaction have to last to be a long-running transaction?" jokes/questions).
Here are a few articles that do a great job of describing the BizTalk Transaction features and how to use them effectively: - Charles Young: Transactions in BizTalk Server 2004 Orchestrations and BizTalk Server 2006: The Compensation Model
- Richard Seroter: Transactions and Compensations using BizTalk Server
- The sentence "put the message back where I got it from" can be either a very good thing, or a very problematic thing. It basically relates to leaving stuff as you found it; in particular, leaving the message back into its origin (thus relating to the transactional concept of "nothing happened here, move along")so that you can try processing it again later on and hopefully it will succeed at that time.
The problem with number 3 is that it (a) isn't always possible, and (b) it isn't always a good idea.
It might not be possible to put the message back where you got it if someone was pushing the message to you instead of you pulling it from somewhere. If you had a SOAP/HTTP WebService exposed that received a message from someone else, then you probably can't put the message back where you got it from!
On the other hand, this is a very common model for queued messaging systems: If you run into an error processing the message, you put it back into the queue and try again later. And this works great many times and can simplify error handling a great deal.
The point where this becomes a problem is when you rely on this as your only error handling mechanism. If you blindly send the message back to its origin to retry processing for any and all errors and a message comes in that always fails, you've got yourself a poison message!
 I've already talked about Poison Messages in the past, so I won't comment much more on them. But there are other things you can keep in mind to improve the "back to the past" error handling technique, particularly if you don't care about message processing:
I've already talked about Poison Messages in the past, so I won't comment much more on them. But there are other things you can keep in mind to improve the "back to the past" error handling technique, particularly if you don't care about message processing:
- If you can identify and classify the source/cause of the errors, you can make your orchestration smarter about how to handle them. For example:
- Can you distinguish transient error conditions? For example, a timeout connecting to the database might be a temporary condition because of a network fluke or a server being restarted. Sometimes retrying the operation after a short while is enough to deal with this situation effectively.
- Can you distinguish errors that might require manual intervention to fix? Example: Validating an operation fails because some configuration data is missing. This is a case where you want to be proactive and raise an appropriate alert so that someone can get in there and fix the issue. Extra points if you can tell apart conditions that require intervention from a business users and those that require it from a systems administrator.
Notice, however, that in this case putting the message back at the start right after creating the notification is not the right thing to do. People don't react that fast. You need to set the message aside until such time as the corrective measure has been taken and it is safe to try processing it again. - Can you control when the retry might happen? Can you throttle it if necessary? If the answer is no, then you might want to be very careful about using this technique. You could easily increase the system load substantially if lots of messages fail in a short time and you try reprocessing them in a tight loop.
- Be mindful of adapters that provide no ordering semantics. For example, if your original location used the FILE adapter and you put the message back in the original folder, it will likely get picked up very soon again for processing; which can quickly get you back to step 2.
At least with an adapter like MSMQ you can push the message to the end of the queue, which might buy you some time. - Even if you take 1, 2 and 3 into account, you still need to provide a way to deal with poison messages. Keep in mind that what started as a transient error condition can suddenly escalate to a full-blown problem you can't do nothing about, like when that temporary network fluke turns into a days-long outage after some idiot digging a whole outside snaps your network fiber cable in two.
In fact, sometimes you might need to go so far as to completely shut down processing. Sometimes being able to detect that some things that should be working keep failing after an extended period of time and alerting about it can help get things sorted out before they spiral out of control.
These are just some ideas that might help make your system more reliable and more manageable. Some of them do cost money; that is, you have to invest time and development/testing efforts in getting them done, and that's where you're going to have to evaluate what makes sense and what not.
>Technorati tags: Messaging, BizTalk, Architecture