
Windows Communication Foundation supports a pretty extensive XML configuration schema in your app.config or web.config file to configure both service providers and service consumers as an alternative to using code to set things up.
This is a good thing in most respects. What causes problems for people getting into WCF is that the WCF is too configurable: It supports a huge set of settings and the configuration schema isn't really very intuitive, and it's not particularly hierarchical in nature, which makes its XML syntax complicate things further. One just has to look at the figure here to want to sit down and cry.
Instead of using the XML hierarchical nature to represent a service or client configuration, the WCF configuration schema is based on keys (identifiers) and references, similar to how you'd do it in a relational database. Lets separate the different concepts in the configuration schema and view it as a set of related elements. We'll only concentrate on the core elements here.
The server configuration looks a bit like this:
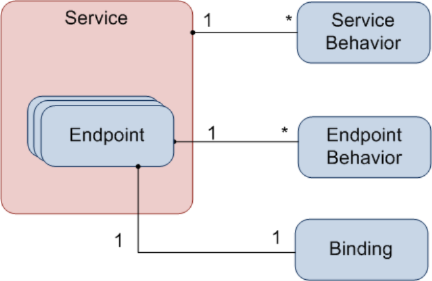
The core concept here is that a Service contains a set of endpoints. An entire service can reference a set of predefined service behaviors (configured under behaviors/serviceBehaviors), and each endpoint can reference a set of predefined endpoint behaviors (configured under behaviors/endpointBehaviors). Each endpoint can reference a predefined binding configuration, unless it is OK with the default settings for the used binding (which will probably be the case).
A client configuration is somewhat similar:
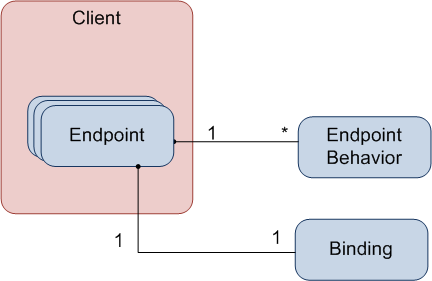
The most important difference here is that a client configuration doesn't specify service behaviors (not needed), but otherwise it is pretty similar.
As I mentioned earlier on, each "reference" shown in the figures above are made using keys. For example, when you define a set of endpoint behaviors, you give it a unique name using the "name" attribute, and then use that name in the "behaviorConfiguration" attribute of the
<service name="VoucherService" behaviorConfiguration="voucherServiceBehaviors">
<endpoint contract="IVoucherService" binding="wsHttpBinding"
bindingConfiguration="voucherServiceBinding"/>
<endpoint contract="IMetadataExchange" binding="mexHttpBinding" address="mex"/>
</service>
</services>
<behaviors>
<serviceBehaviors>
<behavior name="voucherServiceBehaviors">
<serviceMetadata httpGetEnabled="true"/>
<serviceDebug includeExceptionDetailInFaults="true"/>
</behavior>
</serviceBehaviors>
</behaviors>
It really isn't all that complicated, though sometimes, the samples out there don't make it easier for a new developer to understand it by giving stuff confusing names. For example, if you name your service behaviors set "ServiceBehaviors" then you end up later on with stuff like:
<service name="myservice" behaviorConfiguration="ServiceBehaviors"/>
which for a new guy is probably more confusing than needed. I'm guilty of doing this in my own code quite a bit, but it's an habit I should really learn to avoid.
Truth be told, service/client, endpoint and even behavior configuration are not that bad. Each one has a fair set of attributes/elements that you can configure, and the number of attributes you'll use normally is more or less manageable. The only reason service/endpoint behaviors might seem complex is because there are a number of them, each with its own options, and because of how the extensibility mechanism for custom behaviors work. I've talked about this last part before, so I won't repeat it here.
Bindings
I'd say that by far the most complicated part of WCF configuration is dealing with Bindings. The built-in bindings in WCF each has a rather large set of configurable options, some common among them, and a lot of others specific to each binding. For example, here's a typical configuration for the WSHttpBinding, which would be a very common choice for WCF services:
<wsHttpBinding>
<binding name="voucherServiceBinding" closeTimeout="00:01:00"
openTimeout="00:01:00" receiveTimeout="00:10:00" sendTimeout="00:01:00"
bypassProxyOnLocal="false" transactionFlow="false" hostNameComparisonMode="StrongWildcard"
maxBufferPoolSize="524288" maxReceivedMessageSize="65536"
messageEncoding="Text" textEncoding="utf-8" useDefaultWebProxy="true"
allowCookies="false">
<readerQuotas maxDepth="32" maxStringContentLength="8192" maxArrayLength="16384"
maxBytesPerRead="4096" maxNameTableCharCount="16384" />
<reliableSession ordered="true" inactivityTimeout="00:10:00"
enabled="false" />
<security mode="None">
<transport clientCredentialType="Windows" proxyCredentialType="None"
realm="" />
<message clientCredentialType="Windows" negotiateServiceCredential="true"
establishSecurityContext="true" />
</security>
</binding>
</wsHttpBinding>
</bindings>
You just have to look at this to realize that this stuff is just way too much for any normal person to remember. Fortunately, you don't have to configure all those options as there are sensible default values for some of them.
What is complex about all this? It's not just that there are a lot of options to configure; it's that most developers will have no clue what sensible values for many of these parameters are!. Let's be honest about it. Take reader quotas for example. How many people know right of the bat what value they should configure for the maxNameTableCharCount parameter for the service they just created? No? Then let's look at the documentation, by all means:
I don't know about you, but after reading that, I feel I got a pretty good explanation of what WCF does with that setting underneath, but I still have no clue as to what to do with it or how to derive a good value to set it to.
My point here is not to trash the WCF documentation, by all means. My point here is that a lot of the configurable options in WCF are fairly obscure, and most people will just leave that to whatever default value is given to it by the infrastructure. Most importantly, a lot of people won't want to understand that, and just leave happily ignorant about them until they run into some fairly obscure error at runtime, ask in the forums, and someone tells them to just change the corresponding obscure setting.
It's fantastic that WCF allows us to configure even very low level options such as these, but I sure which they could've been exposed in a way that was less in my face. This might be a personal choice, but I really don't want to have to deal with some of this options on a day to day basis, and, to be honest, for a lot of them I don't need/want to have to configure them on an endpoint-by-endpoint basis. I may be in the minority though.
Client vs. Server
Another thing that complicates some of this stuff is that in a lot of the configuration there's no difference between client and server options. Take bindings, for example: You esentially configure the same set of options for a binding on the server and client side. However, some of those options are not stuff a client would usually want to configure or even be forced to configure.
Consider reader quotas: On the server side, these are very important as they help protect your server from malicious clients that might want to attack your services by sending very large sets of data embedded in the requests. You'd normally increase these quotas if you know that your service requires you to accept larger requests. That's good.
But, consider the client: Here, reader quotas are normally not something you care about because you're the one initiating the operation, and a client should normally just accept whatever the service responds and deal with it. Sure, it's important for the client to protect itself and it will normally do that by ensuring it is connecting only to trusted services. It's just inconvinient to have to have to manipulate a bunch of settings just because the service is returning more than 64KB of data (which I'd say it's pretty common).
It's important to note, however, that because of the presence of duplex contracts in WCF, some of these settings will also affect how the client behaves as a "service" when getting invoked on the other way around.
Conclusion
The WCF configuration schema allows you very fine grained configuration of your services and clients. That granularity comes with a price, however: a more complex schema and a bit more work for the developer to understand what the available options mean and how to use them correctly.
