
I've been spending most of today diagnosing a fairly strange issue that has been nagging one of our services in production, and which we hadn't yet been able to fully repro until today. The basic application itself is fairly simple: It's an ASP.NET v1.1 Web Service that calls into a custom ServicedComponent configured locally in a COM+ Server application:
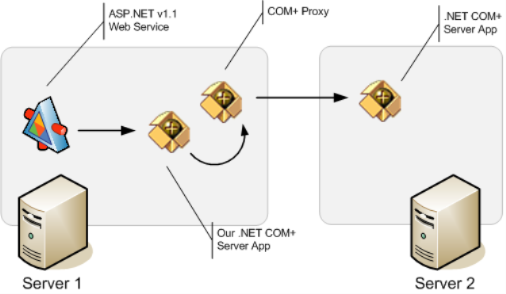
It worked fine for a while, but a few weeks ago we started getting intermittent failures, that manifested themselves when the COM+ application stopped working after a few days of constant running, at which point it would start returning errors when a call to a remote ServicedComponent. The remote component works fine (it's was a preexisting component built for another project that works fine for everyone else). All is running on Windows 2000 Server, by the way.
The really weird issue is that the errors the application would start returning where of two different kinds:
- It would initially start throwing InvalidCastExceptions saying "QueryInterface for interface System.IDisposable failed" when our COM+ component called Dispose() on the remote ServicedComponent's proxy.
- It would eventually start throwing another exception saying "Old format or invalid type library".
Once those started appearing, our COM+ Server Application became a dead-weight. It didn't crash, but *all* requests caused one of the errors mentioned above. Restarting IIS (to reset the ASP.NET Web Service) didn't work, and only shutting down and restarting the COM+ Server application would clear it up.
We had tried several things to try to resolve this, including the obvious things like checking to ensure we were Dispose()'ing everything correctly (we had a few cases that we missed it, and fixed it), completely unregistering our serviced components and registering everything again, checking we had the .NET FX v.1.1 SP1 installed (we did) and so forth, without any luck.
Today we finally got some good information about what seems to be causing the problem, though why it happens is still a mistery to me at this point. It appears something in our COM+ Server application is causing the thread pool to misbehave: It appears almost as if for almost each request received by the server, a new thread was created, used and then discarded. It doesn't get destroyed. It doesn't return to the pool to be reused. It just sits there sleeping.
We discovered this after noticing that the thread count of the COM+ server process just kept growing as we threw requests at it. We didn't notice this before because response time didn't seem to be much affected, and while memory usage was on the rise, it didn't grow steadily and at intervals large chunks of memory would get reclaimed by the system. Obviously, we should've done more extensive load testing to discover this before.
Anyway, the COM+ server process eventually reaches a state where the virtual memory size is around 150MB or more and the Thread Count for the process reaches a little over 7000 (yes, 7000), at which point it would stop servicing requests as I described before. Having discovered this, I got out trusty old Windbg and after doing a smaller repro scenario (after processing just a few hundred requests), I proceeded to take a minidump of the COM+ server process and brought it back with me for analysis.
I've been spending the remaining of the day looking at it, though I must admit I haven't found anything too useful yet. Looking at all the thread stacks (all 93 of them, whoooohooo!), some are easily recognizable and expected, like some RPC and threadpool control threads. However, the vast majority of the threads (around 70) of them show this as the thread stack:
0:000> ~37 kb
ChildEBP RetAddr Args to Child
04eef514 7c59a28f 00000001 04eef52c 00000000 NTDLL!ZwDelayExecution+0xb
04eef534 79233c74 00003a98 00000001 04eef7c0 KERNEL32!SleepEx+0x32
04eef554 79233cec 00003a98 04eef58c 010b5d08 mscorwks!Thread::UserSleep+0x93
04eef564 00e4b69e 04eef570 00003a98 017fc55c mscorwks!ThreadNative::Sleep+0x30
WARNING: Frame IP not in any known module. Following frames may be wrong.
04eef5b4 791d94bc 04eef6cc 791ed194 04eef608 0xe4b69e
04eef5bc 791ed194 04eef608 00000000 04eef5e0 mscorwks!CallDescrWorker+0x30
04eef6cc 791ed54b 00bc82f3 79b7a000 04eef6f8 mscorwks!MethodDesc::CallDescr+0x1b8
04eef788 791ed5b9 79bc82f3 79b7a000 79b91d95 mscorwks!MethodDesc::CallDescr+0x4f
04eef7b0 792e87b7 04eef7f4 03a54298 791b32a8 mscorwks!MethodDesc::Call+0x97
04eef7fc 792e8886 04eef814 03a5a598 792e87c4 mscorwks!ThreadNative::KickOffThread_Worker+0x9d
04eef8a0 791cf03c 03a5a598 00000000 00000000 mscorwks!ThreadNative::KickOffThread+0xc2
04eeffb4 7c57b388 000a7898 006f0063 00000003 mscorwks!Thread::intermediateThreadProc+0x44
04eeffec 00000000 791ceffb 000a7898 00000000 KERNEL32!BaseThreadStart+0x52
From this, it would appear as indeed the threads were being put to sleep right after processing a request. But why, and by what, is still something we're trying to figure out.
Some things might be worth mentioning at this point:
- We're not manually creating new threads in our code.
- We're not doing any async operations or calling any async delegates, so it's not a case of us forgetting to call EndXXX() somewhere.
- We're not explicitly using the managed ThreadPool anywhere.
- We're not hanging on to the request thread (after all, until the error happens we're getting responses right away to the calling Web Service).
We still have a few things we want to try out, and we're considering getting the most recent COM+ rollup package of hotfixes for Windows 2000 onboard to see if it helps, though we haven't seen anything specific in the KB articles that points directly at a problem like ours. I'm still very reluctant to say this is a platform bug, though; there might be something we did to cause it and we're just missing it.
If anyone happens to have any ideas or suggestions, they would sure be appreciated!
Update 2006/09/30: I've been playing with this some more, and realized I was doing something stupid: I totally forgot about loading the SOS (Son Of Strike) extension to the debugger. With this in hand, I've been able to discover a few extra things:
Using the !comstate and !threads commands reveal that most of the threads being created are not even related to the COM+ thread pool at all. Here's the breakdown of threads:
- 1 is the finalizer thread (thread 13)
- 1 is a threadpool worker thread (thread 19)
- 9 threads are in the MTA, and 1 in the STA
- All the rest of the threads are not even in a COM apartment at all.
Looking at all the other "weird" threads with SOS, I was able to dump a more useful stack trace:
0:000> ~37e !clrstack
Thread 37
ESP EIP
0x04eef58c 0x77f883a3 [FRAME: ECallMethodFrame] [DEFAULT] Void System.Threading.Thread.Sleep(I4)
0x04eef59c 0x03943e37 [DEFAULT] [hasThis] Void Microsoft.Practices.EnterpriseLibrary.Configuration.Storage.ConfigurationChangeWatcher.Poller()
0x04eef7c0 0x791d94bc [FRAME: GCFrame]
Humm... interesting. We do use the Enterprise Library for database access in this application (though it's just calling a few SPs that manage a transaction log), and now it appears it's ENTLIB creating watcher threads. Certainly something we'll look at monday morning; we may be initializing something wrong and I have an idea as to what might be.
BTW, did I mention Windbg + Symbol Serve
r + SOS rocks?
Update 2006/10/02: Yep, verified; the problem was the Enteprise Library. We got rid of it, and the problem went away. Go figure!
Technorati: Web Service, WS, Enterprise Services, COM+, .NET
