
Winterdom
by dæmons be driven - a site by Tomas Restrepo
The BizTalk Server 2004 documentation is rather scant on the topic of creating
schemas overall, but, specifically, it is surprisingly poor at explaining the
basic concepts behind the flat file extensions to the designer.
So, let's try to clear up a few of the concepts by creating a simple, yet
interesting Flat File schema that parses CSV (Comma-Separated-Values) file.
Let's start with the basics: What rules are there for a CSV file, in plain
text?
A CSV file contains a set of records, separated by a CR/LF pair
(\r\n). Each record contains a set of fields separated by a comma (,). If a
field contains either a comma, or a CR/LF, then it must be escaped by enclosing
said feed between double quotes.
There is certainly more to a CSV file, but let's use this definition for now to
start this tutorial.
The first thing we need to do is create a new Schema, let's call it
"CSV". Once we created the schema, we need to tell BizTalk that is we
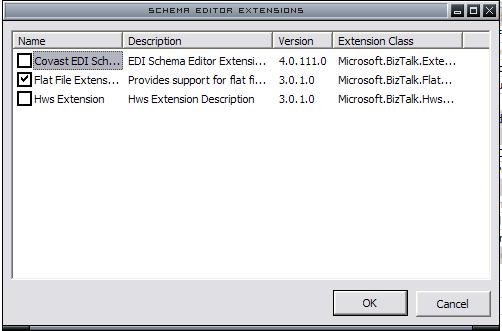
want to enable the flat file designer. To do this, selecte the schema, open the
properties window; find the "Schema Editor Extensions" property and
enable the appropriate one, as presented in the following image:
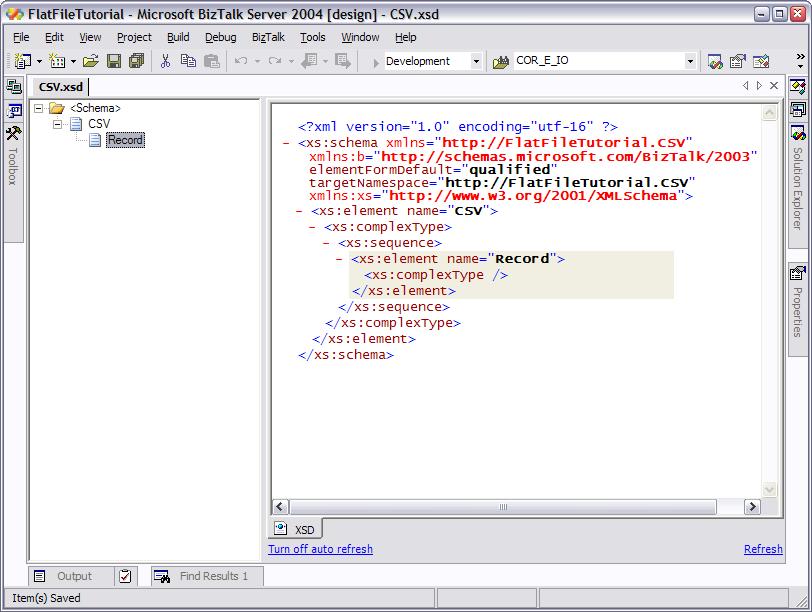
Now, let's rename the root node of the schema to a more sensible name, say
"CSV"; this will be the root of the XML document generated from the
CSV file contents. Since the CSV file contains a set of records, let's add a
new Record Element underneath the CSV node and call it "Record", as
well.
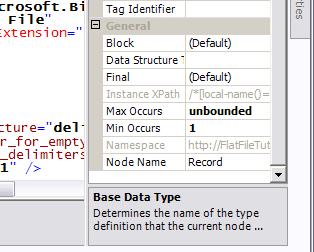
The Record node can be repeated any number of times, so let's set the minOccurs
and maxOccurs properties as appropriate:
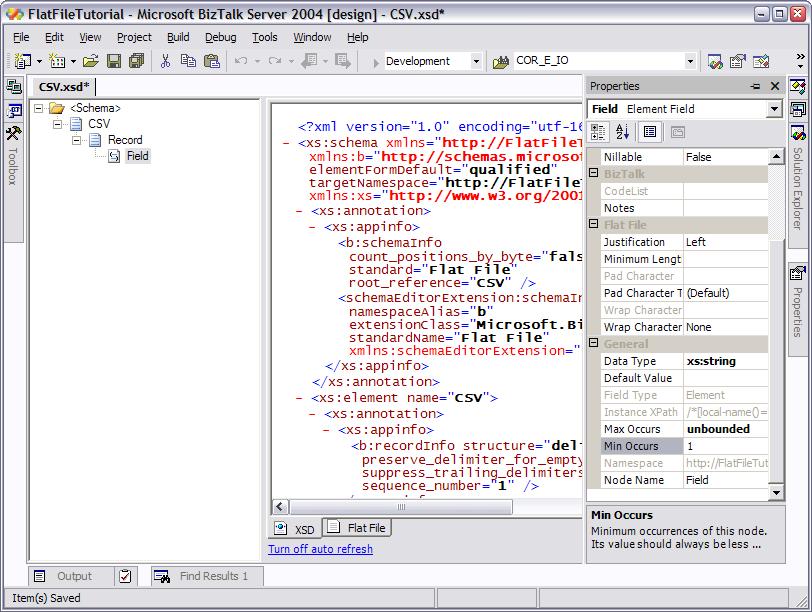
Each record is composed by a collection of fields, so we want to add those as
well:
Now comes the interesting part, which is making it deal with the Flat File side
of things. Let's start inside out.
First, we want to ensure that the schema parses correctly each field inside a
record. So, we'll go ahead and select the Record node and open up its
properties. Here, we need to tell BizTalk that this is a delimited record, not
a positional one, so we set the value of the Structure property to
"Delimited".
Next, we need to tell it what kind of delimiters it uses (a comma). For this,
we we'll use the Child Delimiter set of properties of the Record node, and set
them like this:
| Property | Value |
|---|---|
| Child Delimiter Type | Character |
| Child Delimiter | , |
| Child Order | Infix |
| Preserve Delimiter for Empty Data | yes |
What this means is that each field in each record will be separated by a
character (a comma), and that the position of the delimiter between the record
will be between each field (that is, infix). Other possible values of the Child
Order property include Postfix (which means it will always appear after the
field, even after the last one) or Prefix (which means the delimiter always
appears before the field, even before the first one).
To understand the difference between this three values, let's consider an
example of what they would parse:
| Infix | field1,field2,field3 |
| Postfix | field1,field2,field3, |
| Prefix | ,field1,field2,field3 |
Clearly, it is the infix case what we want. Enabling the Preserve Delimiter
for Empty Data property means that fields with no value will not be ignored,
but serialized as empty elements (and that they'll have the necessary
delimiters added, to enable things like "March, Robert,,Peter").
Now that we can parse each record, we need to tell BizTalk what separates each
record in the file, which is a pair of CR/LF. To do this, we need to select the
root element of the Schema (CSV) and configure its properties like this:
| Property | Value |
|---|---|
| Structure | Delimited |
| Child Delimiter Type | Hexadecimal |
| Child Delimiter | 0x0D 0x0A |
| Child Order | Infix |
Here we're telling BizTalk that the delimiter is not a specified as a printable
character, but rather as the hexadecimal values of the characters. The way to
specify the characters is not very clear in the documentation, so keep this in
mind:
One suggestion I'd make to the BizTalk team in charge of the schema editor
would be to allow us to use, in this cases, the "Character" delimiter
type and instead put the escape sequences as the value (say, "\r\n").
That would make it much simpler and more intuitive, in my opinion.
Armed with this configuration, we can try the schema for the first time.
Configure it so that we can validate the schema against a native instance, and
put this in the input text file:
Restrepo,Tomas,27
Brown, Robert, 34
Smith, Lauren, 24If we try that, we'll see this result:
Restrepo
Tomas
27
Brown
Robert
34
Smith
Lauren
24
Great,this worked! However, it has a few minor things that don't quite act like
we want to. The first one is the empty spaces on some of the
values, which we might like to avoid. To do so, we could tell BizTalk that
fields might be padded with empty spaces, by selecting the Field node and
configuring the following properties:
| Property | Value |
|---|---|
| Pad Character Type | Character |
| Pad Character | (empty space) |
| Justification | Right |
However, this doesn't quite solve the problem, since if we had trailing
spaces, instead, they wouldn't be removed. This is a side-effect of the value
of the Justification property, since it tells BizTalk where the padding would
go. Unfortunately, there's no such thing as a "Justified" setting,
only left or right are allowed.
A second problem this schema has is that if there are empty lines on the file
(say, traling CR/LF pairs) then BizTalk will generate empty Record
declarations, like this:
To be quite honest, I don't know yet how to avoid this, so let's leave that
aside for a while. We'll come back to it eventually.
The biggest problem with our schema right now, is that it won't allow fields
that contain embedded ";" or CR/LFs, since there is no way to escape
them. In flat file schemas, there are two ways to solve this problem:
Number 2 is what we want in order to comply with the CSV definition we gave
above, which requires us to wrap problematic fields in double quotes. To do
this, we'll select the Field node and configure the following properties:
| Property | Value |
|---|---|
| Wrap Character Type | Character |
| Wrap Character | " (double quote) |
With these new properties configured, we can parse the following document
correctly:
Restrepo,Tomas,27
"Brown,row a
lot", Robert, 34
Smith, Lauren, 24
Restrepo
Tomas
27
Brown,row a
lot
Robert
34
Smith
Lauren
24
And that's it for now. As you can see, it is not all that hard to use, although
it can be a little bit confusing at times. Hope this helps anyone!