
One of the most interesting patterns I've seen for BizTalk integrations is McGeeky's Sequence Guards pattern, but, until now, I hadn't had a chance to actually take advantage of it.
There are a few main advantages to using a sequence guards-like mechanism to guarantee ordered processing instead of the usual singleton orchestration using correlation sets and convoys:
- Unlike convoys, sequence guards do not require that all messages are received from the same source (receive port) or that the receive protocol guarantees in-ordered delivery. This frees you up in some escenarios to simplify message processing, and, more importantly, can make error recovery simpler.
- The usual singleton orchestration convoy used to ensure ordered processing can be very painful to version, almost requiring you to ensure that the original orchestration is never touched and never terminated, since it will brake your processing and possibly loose messages or the order they arrived in. With sequence guards this is somewhat easier (though you still need to be careful).
While exploring the use of the sequence guards patterns, I've done a few minor variations, which might be interesting to some of you.
Message Ids
The hard part about implementing sequence guards is how to determine the order from the message contents. McGeeky's sample uses a very simple mechanism in which each message carries a simple integer field which tells you the position of the message in the sequence (a monotonically increasing field). This works very nicely, but it depends on numbers in the sequence order never being skipped (which can actually happen sometimes).
In my case, I didn't have a single sequence on which to apply the guards. Instead, what we had was multiple message sources, and needed to process messages in order for each one, but not among them. I also didn't have a simple sequence id field. What I did have was each message carrying a unique ID (GUID) generated at the message source. What I figured out here was that, since we also controlled the application sending the messages and it tracked which messages it had recently sent, I could also add another field to the message which had the unique message ID of the previous message. In other words., each message carried a header containing the message source ID, this message ID, and the previous message ID.
Applying the sequence guard pattern from there was a snap: I could define a guard as a message containing a message id and a message source id. In effect, I could create the guard correlation based on the previous message id instead of the id of the message being processed (as McGeekys's sample does). Thus, each time a message was processed succesfully, a new guard would be created using the ID of the message just processed (not of the next one to be processed).
Replaying messages
Allowing the user to resubmit messages that failed processing in a convoy scenario can be a bit tricky, since it requires pausing processing until the problem is resolved and reinserting the failed message into the processing pipeline ahead of queued messages that might have arrived after it.
In a sequence guard implementation, however, resubmiting messages is somewhat easier, since message processing is paused in a natural way until the right message guard is generated, and that won't happen until the message is successfully processed. However, there are still some issues that need to be taken care of for this to work reliably:
- Supporting the resubmit: Since the first attempt at processing the message consumed the original sequence guard, you need to re-generate it to allow the message to be processed again once you resubmit it. In our project, we solved this quite easily: The sequence guard orchestration traps the processing error and, instead of simply terminating, just resends the original message guard again. This provisions a new orchestration instance that will sit waiting for the resubmitted message to retry processing.
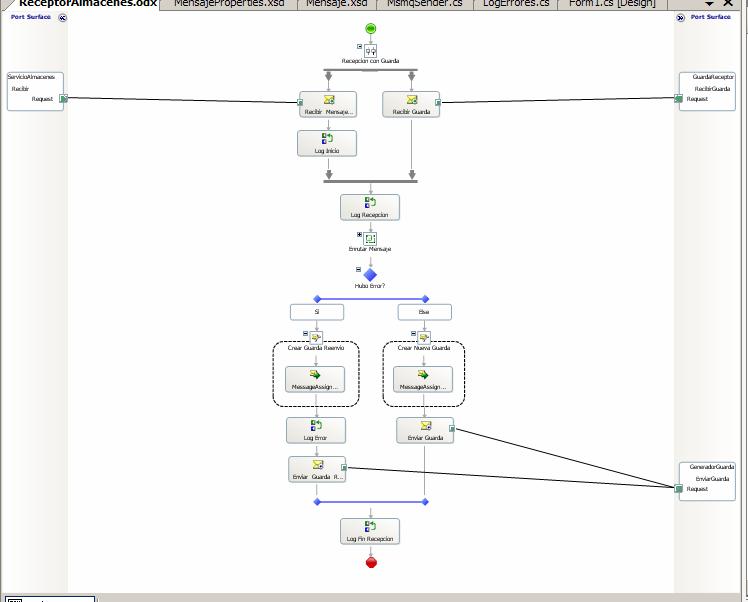
An alternative way of doing this might be to generate the message guard when you resubmit the message itself. Or, you can simply create a separate entry point (receive port + orchestration) for resubmited messages that simply skips the sequence guard receiver completely and instead goes straight to processing. However, you still need to make sure that the new guard is generated so that the next message waiting can be processed.
- Time to error handling: One downside of this in a sequence guard scenario is that if the message receive rate is high, and processing is paused waiting for a message to be resubmitted, then a lot of new orchestration instances will be created (one for each message received), and each of those instances will just sit there waiting for the right guard to be triggered. This, in fact, creates a kind of domino effect unleashed once the message is succesfully processed and the message guards start flowing through the system again. In a conventional convoy scenario, however, messages are held off either at the receive protocol side (say, a queue) or at the message box waiting to be picked up by the receiving orchestration. Whether this is a problem for you might depend on the exact scenario.
Provisioning the sequence
In convoy scenarios you always need to determine both at design- and runtime just what will constitute the first message in the ordered set of messages. In other words, you still need to figure out what set of properties, or what message characteristic will trigger the convoy orchestration. In sequence guards implementation this is still true, but it might be easier to handle in some cases, since the order is more clearly defined by the sequence itself the pattern is based on.
However, one downside of the way the sequence guard pattern works is that you still need to provide a guard for the first message in the sequence (it's not selective). In many scenarios, this can be done manually as part of the deployment process, if you only have a fixed number of sequences and you know at this point in time where the sequence starts. However, in other scenarios this might not be feasable, and so you should look into ways to make the infrastructure self-provisioning in the sense of allowing the BizTalk implementation itself to provide the initial guard that allows the first message in the sequence to be processed automatically.
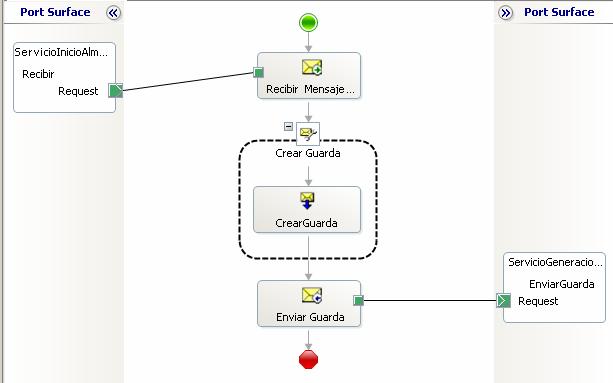
In my case, I could count on the fact that the first message sent from each message source would contain an empty GUID in the previous message ID field. In other words, each sequence was started with a message that had a particular value in a particular field. With this, I could easily solve the problem and make the infrastructure self-provisioning for each message source by simply creating a parallel orchestration that subscribed to messages with an empty GUID in the field, and simply generated the appropriate message guard, thus freeing the actual sequence guard orchestration to process the initial message.
The power of this was that it made the process of adding new message sources much easier, since there was no need to configure or prepare new orchestrations for it.
