
A couple of years ago I worked on a project for an important Bank here in Colombia on an ASP.NET-based application to provide on-line risk assesments for the bank's customers in the branch offices. The purpose of the application was to provide employees in the bank a tool to quickly analyse whether an existing or potential customer was subject of receiving a loan and other financial products, while the customer was sitting in front of them. So response time was arguably an important part of the application's experience.
One of the challenges we had to overcome in building this tool was that in order to provide a meaningful assesment, we needed to aggreate information coming from multiple data sources, both internal and external to the bank. One of these was a set of risk analysis models the bank had developed a few years earlier that took basic information about the customer (like where he lived, how many cars he had and so on) and provided a risk score based on some internal logic.
The problem was that these models in particular had been designed and implemented to work in batch-oriented scenarios: They were basically a set of executables that took a flat file as input with one customer per line, and they wrote a new flat file as output containing the score calculated for each customer on the input file. Obviously that was not useful to how we needed to execute the model, given that we had to provide an answer as fast as possible to the customer, but, unfortunately, rewriting the existing risk models was not feasable.
Fortunately, we did manage to provide a solution to the problem that gave us decent performance and allowed us to reuse the existing risk models in a fairly robust way: Auto-batching requests. It turns out that most of the time required to run one of these risk models was spent actually setting up the internal program structures (we didn't have access to the code, but this could be inferred from the actual behavior); once they were set up actually analysing a specific customer entry was just a very small fraction of the cost. So, for example, running the model for say, 1 customer, took roughly the same ammount of time (+/- 10%) as running it for 10 customers as input. The question then was how to take advantage of this fact by allowing the system to batch incoming requests in such a way that the response time for each request was not affected in a very significant way by the added delay in batching.
Basically what we came up with can be glimpsed from the following diagram:
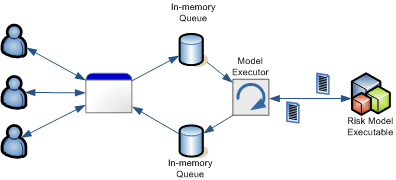
- Users sent requests to perform risk assesments to the ASP.NET application.
- When a risk model needed to be executed, instead of running it directly, we entered the request already prepared (that is, all necessary data mappings and formatting already having been done) into an in-memory queue. Each risk model had it's own independent queue.
- An executor component running in a background thread basically locked the queue every X number of milliseconds (usually set to 1 second) and extracted all pending requests from the queue, then released it.
- The executor now was free to continue by actually writing the input flat file, and running the risk model executable on it.
- Once the executable was done running, the executor took the output flat file, parsed it, and correlated each line in the output file to a request in the input, adding the corresponding output line into another in-memory queue (or rather, an associative array, really).
- The thread that originally queued the request then simply was notified that the output had been produced (via an event) and then was able to retrieve the response from the output in-memory queue.
So far, this is a very simple solution. In reality, things weren't quite so simple, and we had to add a few extra features to the executor to ensure it was reliable, because of the way the risk model executables had been built. The risk models had a very unfortunate "feature": If it was unable to calculate a risk score for one line in the input file, it would simply fail printing an obscure error message to the console, and most of the time failed to produce an output file at all. The error message was useless, by the way, because it didn't tell you which line in the input file caused the problem. Also, at least one of the risk model executables had this annoying tendency to just hang when an error was detected instead of cleanly terminating its process. Because of this the code actually had a lot more logic to deal with these situations, including timing out model execution and forcibly terminating the process, as well as completely aborting an entire batch in case of errors. Fortunately, we came up with a way that ensured that all clients that had submitted a request into the queue got a response (error or otherwise), which allowed for retries in some conditions.
In retrospective, this was a fairly logical solution to the problem at hand, and it actually worked very nicely for our purposes. While it certainly could've been better, it was very adequate for our needs and the entire tool was a great success with the bank.
